How to transfer a real-time AI in the Cloud to a web app

At Baracoda, the core of our products is to build advanced, real-time AI algorithms that
- track users’ daily habits & gestures,
- deliver smart insights about their daily health practices,
- recommend improvements to their routines.
The insights and recommendations can focus on various different health metrics, including skincare (CareOS.com), oral care (kolibree.com) and hygiene, and posture and balance (bbalance.io ). Our algorithms are bundled as C++ libraries and are typically embedded inside our mobile apps to leverage processing power. Additionally, some of the pre-processing happens directly in the connected object.
This article focuses on an algorithm developed for Oral Care. It processes acceleration and gyroscopic data from our connected toothbrush to infer whether there are any unbrushed or underbrushed parts of the user's mouth as well as whether they are brushing are the correct speed and angle.
The algorithm works by creating a session which receives data retrieved from the toothbrush. It regularly sends notifications to the user to show them in real time if they are properly brushing their teeth or not. Finally, once the brushing is complete, the user can retrieve a full range of statistics about the session. A session lasts for as long as the user is brushing their teeth, which is usually around 2–3 minutes.
Embedding this algorithm inside the associated mobile app is simple and straight forward: the app simply adds the library and is then able to access the algorithm.
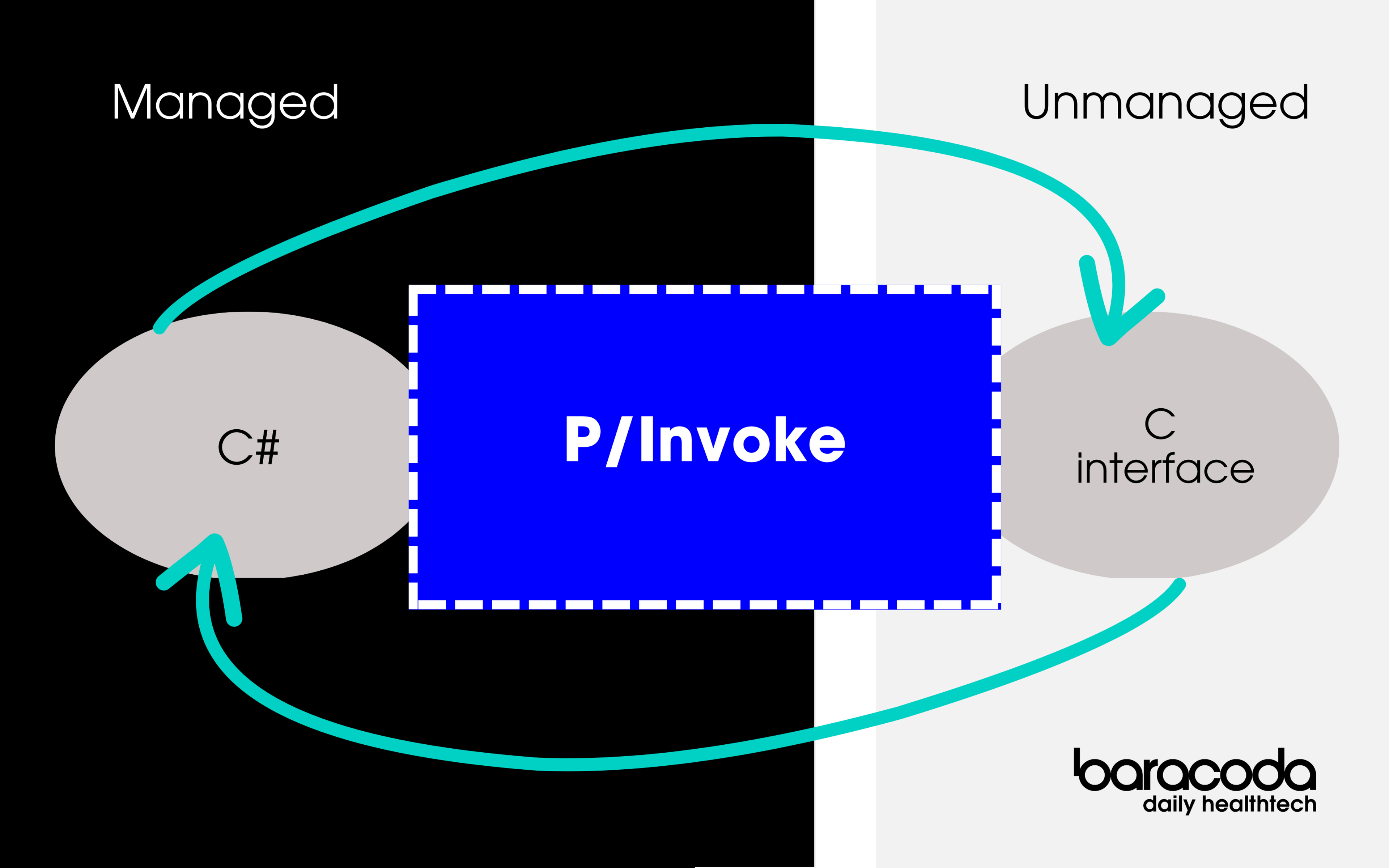
Recently however, we needed to use this algorithm in a real time activity inside a web app for a WeChat mini program. Rewriting the algorithm in JavaScript to embed it inside the web app was not an option, as doing so would expose our intellectual property. Our solution was to stream the toothbrush data to an API that would process the data through our algorithm and then send back the results. Simply put, we sent the library through an API that keeps the state of the algorithm to feed the data collected from the toothbrush via the web app.
Table of contents
Key technological choices
Since the algorithm is in C++, it might seem like a good idea to develop the service in C++ in order to easily interact with the library. However, anyone who has ever worked on backend C++ knows that the amount of boilerplate and crash management tasks are extensive. We needed something simpler. Since our backend codebase is mostly in Python, it seemed logical to keep using Python. We then used SWIG to interface the C++ library with Python code.
Since the API needs to be used by a web app and to stream data, we decided to use Websockets. Websocket libraries are well integrated in both JS and Python and offer good performance.
To simplify serialization tasks and interoperability between the backend and the web app, we chose to use protobuf to define the packet format. Although it can be a little strict when it comes to defining structures, it speeds up development time quite significantly since the backend only needs to define the structures associated with requests and responses and then just share a .proto file with the client team, making sure they won’t need to recreate structures and serializers of their own.
General architecture of the service
In a traditional event based websocket server, you create connections, wait for the input, process this input, and send a response asynchronously, meaning there is only one thread inside the server.
This would not work for us.
The fact that the library is written in C++ presented a challenge: although exceptions are elevated by the SWIG interface to the Python code and therefore can be mitigated, we cannot prevent segfaults from happening. If the server is structured as a single thread, asynchronous loop, a segfault would crash the whole algorithm. As a result we would lose every single connection and state held by the server, forcing the users to restart their sessions all over again.
In order to mitigate this, we decided to isolate every single state inside its own subprocess, forking the server every time a new session starts. A pipe is created between the main process, that contains the websocket event loop, and each subprocess. The main process only serves as a proxy between the websocket connections users create and the subprocess in which the algorithm and its state are kept.
This architecture enables the algorithm to crash without crashing the whole server, only the subprocess that hosts it. The subprocess can then be joined and the server can carry on.
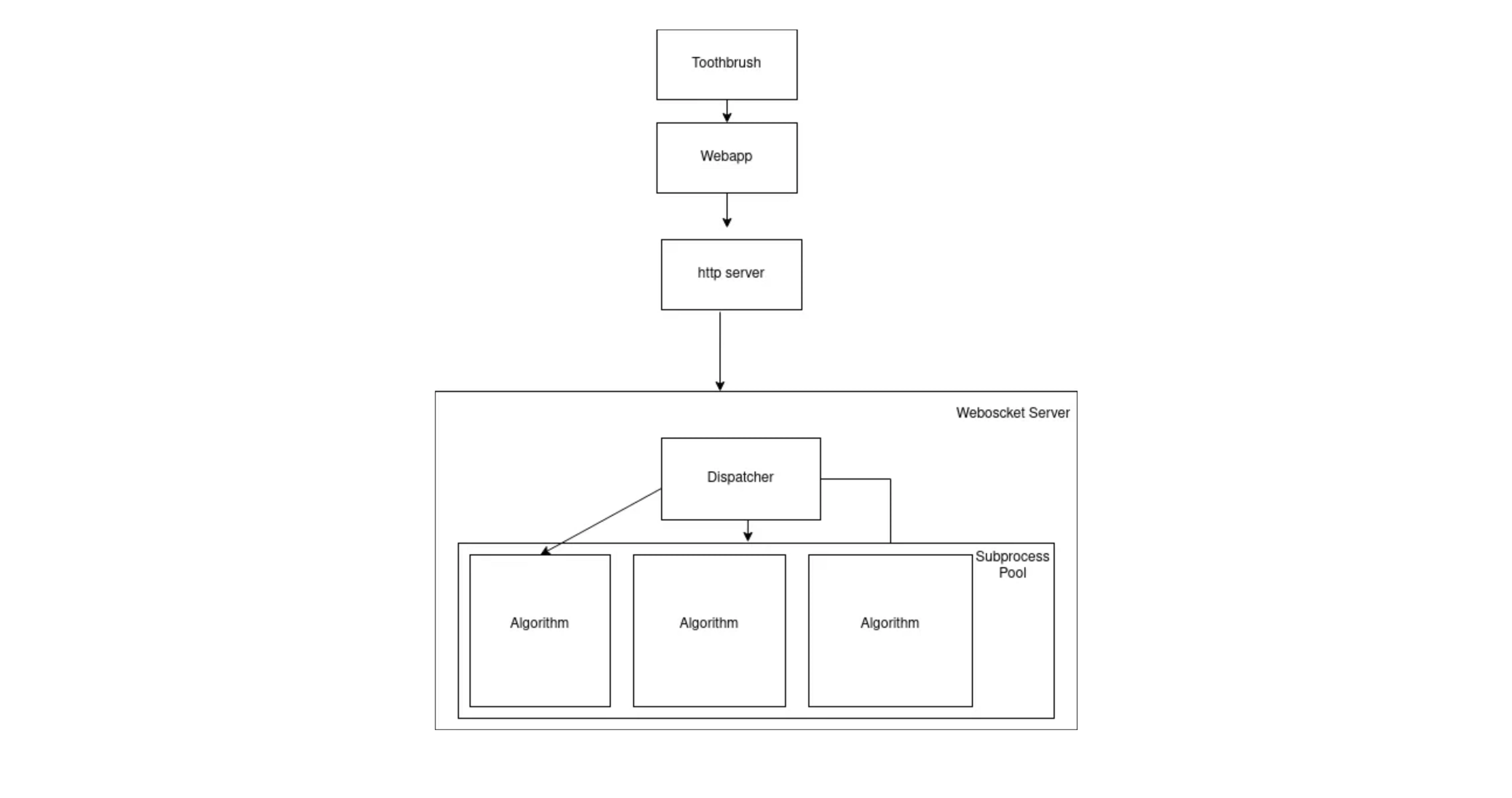
Diagram of the general workflow of the application
Performance and latency concerns
Since the point of this application is to provide real-time feedback on the user’s brushing, the algorithm needs to be fed regularly in order to give proper feedback. That is why the toothbrush generates 50 data points per second. Every 25 data points, the algorithm gives feedback. That means 2 points of feedback per second. With the integration of the algorithm in the backend, the webapp would need to send 50 requests per second and get 2 results per second.
Due to its unique architecture, we were concerned about performance. When you think about it, every time a client sends a request to the API, the main process reads it and transfers it to the subprocess through a pipe. The subprocess the reads it, processes it, and writes the response to the pipe before the main process reads it and writes it to the websocket. That means there are 3 reads and 3 writes per request.
For the service to be useful, it must perform this task 50 times per second.
First, we aimed to determine how much time the subprocess system added to the response time, as well as the algorithm. For that, we set up a test server that responded to a simple ping, in order to have a reference of the server’s response time when nothing happens. Then, we did the same thing with subprocesses but without the algorithm. Finally, we ran a full test to represent the typical use case. The test client would send 50 data points and await for the responses. The results were the following, tested locally on a machine:
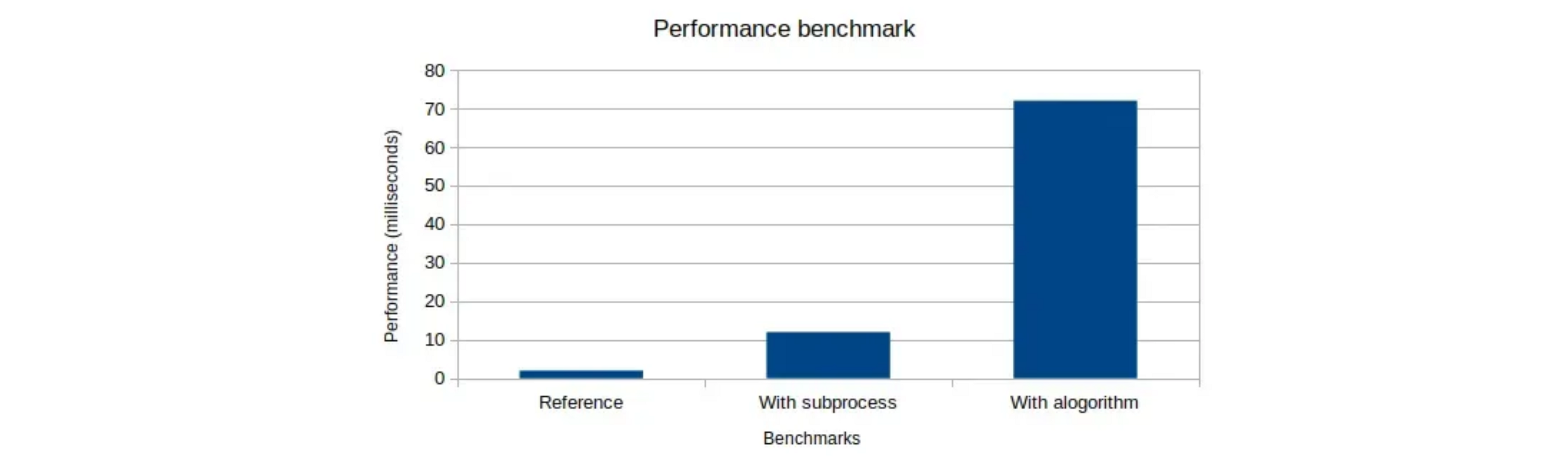
This test showed that sending 50 data points per second was definitely possible, the only limitation being network latency.
At scale however, with several hundred concurrent clients, the latency would increase to a point where it takes more than a second for the 50 data points to be processed. This was due to the fact that the algorithm is very CPU intensive, which meant that running too many instances of the algorithm would eventually overload the CPU.
Horizontal scaling
Since the service is deployed inside a pod hosted by Kubernetes cluster, the simplest answer to this was to use Kubernetes’ HPA to scale up when the CPU gets overwhelmed. The issue is that our service is stateful. This isn’t a problem for scaling up, but it is for scaling down. You do not want to kill a pod on which sessions are still running.
The way Kubernetes works when scaling down is that it will flag pods for termination. Once a pod is in “Terminating” status, no new connections will be routed to the service. However, the connections that have already been established will still function. Kubernetes waits for a certain amount of time, called the grace period, and then kills the pod. The default grace period is 30s. This might be enough for a stateless app like a website, for example, but a tooth brushing session can last for 5 minutes.
To fix the scaling down issue, we therefore set the grace period of the pods containing our server to 10 minutes, just to be on the safe side. That way, when a pod is terminated during a scale down, the current sessions will have time to finish properly before the pod is deleted.
Pooling
Another way we improved the algorithm's performance was by pooling subprocesses. Forking a process is a costly operation. Forking and joining every time a session is started or ends was not ideal.
The custom process pool we built will fork if there are no subprocesses available. When a session ends, it will put the subprocess on standby, rather than joining it. Then, when a new session starts, it will reuse the old process which will overwrite the previous algorithm session to start a new one.
This approach allows for a faster overall start to sessions. It also allows us to prefork several subprocesses during service startup.
Monitoring
Making sure the pods are up is easy, since many automated alerting tools exist for that purpose. However, functional monitoring, that is making sure the service is actually up and running properly, requires launching a test session to see if it completes correctly. Since we are using custom protocols and data structures, we couldn’t use standard tools to do this.
We therefore used a custom client that we ran inside a recurring Jenkins pipeline. This pipeline enables us to start a new session, sends enough data points for a session to be considered complete, then requests a full checkup. The client is able to throw different errors, mainly if a request fails or if it times out.
When the pipeline fails, these errors are then sent to a Slack channel, alerting the whole team of said client's failure.
Conclusion
Transferring our algorithm server-side allowed us to provide a proper API for a web app to use it, but it also offers us the opportunity to expand the number of potential devices and apps that will be able to use it without worrying about its integration. Our multi-process architecture made it possible to process each session safely. The only downside to this approach was the heavy resource consumption. The reason is that in order to ensure a smooth brushing session and a true real-time experience, we couldn’t allow low latency and therefore opted for an aggressive scaling policy.