How we built a continuous integration platform with Monorepo


One year ago, a new ambitious project started at Baracoda. We — a new multidisciplinary team — were assembled to work on a common project. When we started our journey, it was obvious that a unique repository for the whole team would facilitate our work.
We already had some experience with monorepos, but at a smaller level, always focused on one specific technology. This time, we wanted to only have one repository that handles all our different stacks.
After almost a year of use, we believe it’s the right time to share our feedback.
Table of contents
Why use a Monorepo?
Let’s start by explaining our environment. Our team contains around 25 people with different areas of expertise: AI, Android, Backend, DevOps, Firmware, iOS, and Web. We are using GitHub as a Git hosting service, and CircleCI as a continuous integration and continuous delivery platform. We are used to working with trunk-based Development, with short-lived feature branches.
Since our team is building one common product, we are developing several inter-dependent subparts that we call modules. Having all of them in the same repository allows us to run end-to-end integration tests, share common resources, and fail fast! Moreover, it also enables us to enforce best practices at the monorepo level, and to manage only one Continuous Integration (CI) configuration.
For sure, it comes with drawbacks: the size of the repository is growing quickly and the releases can be more complicated to manage.
The CI configuration is also more complex. Using the naive approach and rebuilding everything will quickly show its limits. We use various CircleCI tools available to handle this.
At the time, we thought that the benefits outweighed the drawbacks. The good news is that one year later, we still feel the same way.
What about the CI?
Before starting this project, most of our repositories were pretty simple: one technology and a simple pipeline with a few workflows (build, test, deploy).
Here, our repository hosts a large variety of languages and technologies, the number of developers involved is far bigger than usual, and the project can be divided into several modules, with or without interconnections.
We also don’t want one person to be in charge of every piece of the CI. Instead, we want to have each sub-team responsible for its own workflows. It means that our CI architecture has to be easy to manage for people who don’t have a deep knowledge of the whole structure.
Efficiency is also a critical point: we don’t want to wait for hours for it to finish building. We have to think twice about how to manage the cache, how to split the jobs, etc…
Moreover, with climate change, the more efficient we are the better it is for our planet! Basically, we try to save penguins by making our CI smarter!

How does it work?
The naive approach is to put the entire configuration in the mainconfig.yml and to build everything every time. However, you quickly face several issues: the configuration file will become enormous and hard to manage, the build time will increase very quickly and your CircleCI credits will disappear like water during a heatwave!
So, how do we make it smarter, then?
Our starting point
We started this journey by using circle-advanced-setup-workflow as our base.
It lets us define which folders we want to use as modules and the dependencies between them. It also provides the logic for detecting which modules were modified by the latest commit and which modules to build. This is exactly what we needed to get started!
Does all of this seem a bit fuzzy? Let’s dive in!
Construct the pipeline dynamically
Being able to dynamically choose which workflows will be executed is critical in a monorepo environment: you cannot afford to build the entire codebase again and again for each commit.
This type of behavior is possible thanks to dynamic configuration. Rather than use a static configuration file, it lets you generate a configuration on the fly.
When using this feature, the pipeline is run in two steps.
During the first step, a workflow called setup-workflow aims to check what modifications have been made in the repository. Based on this information, it generates a new configuration file with workflows from the modules that need to be built.
The second and last step executes the generated configuration file, as would be the case in a “classic” scenario.
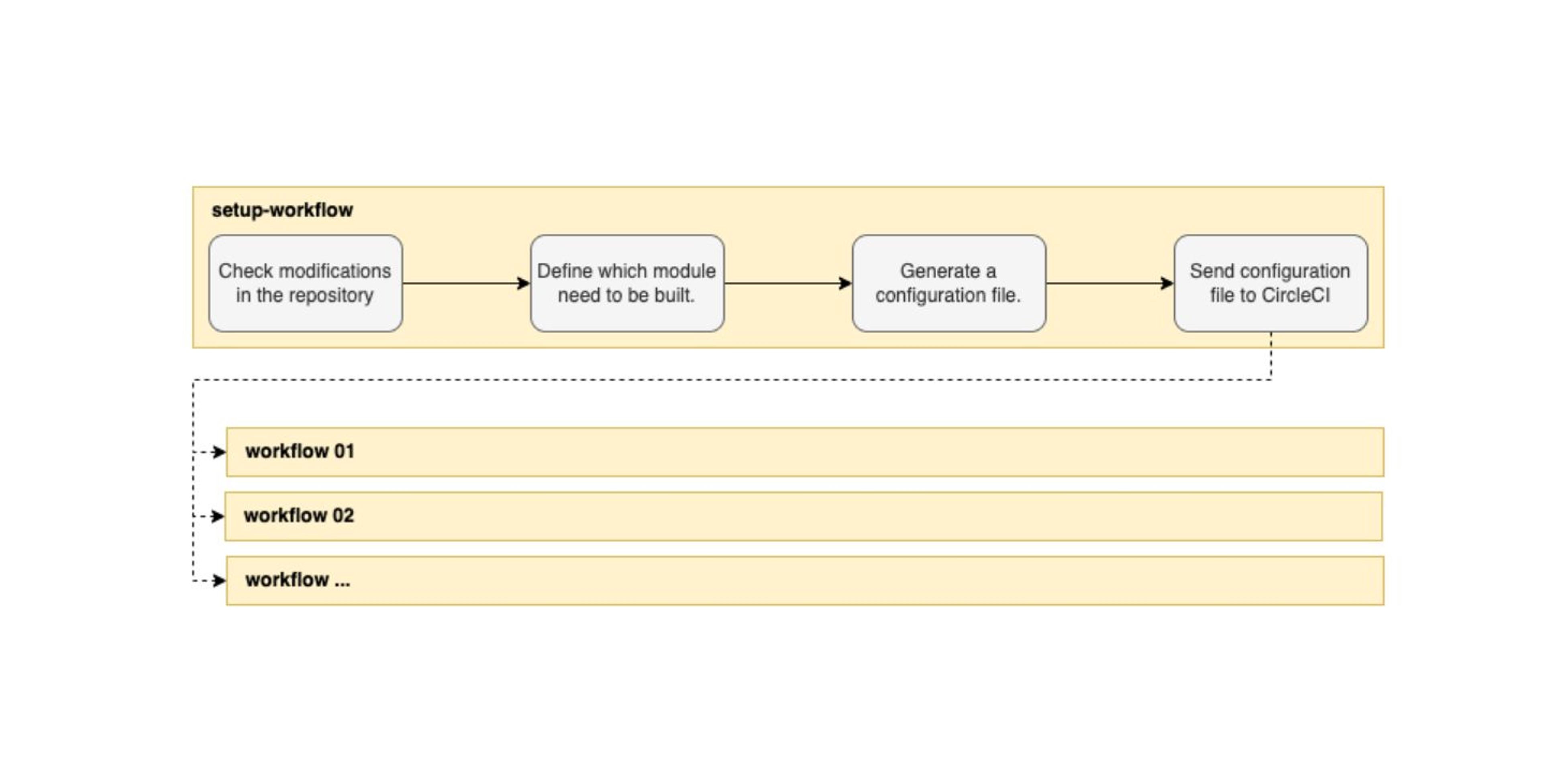
This step is critical since it allows us to select specifically what we want to run. It’s now time to see which module has to be built.
Only build the code impacted by the changes
We already know we don’t want to rebuild everything, but how can we determine the modules impacted by the changes? Dependencies seem to be a good indicator of that!
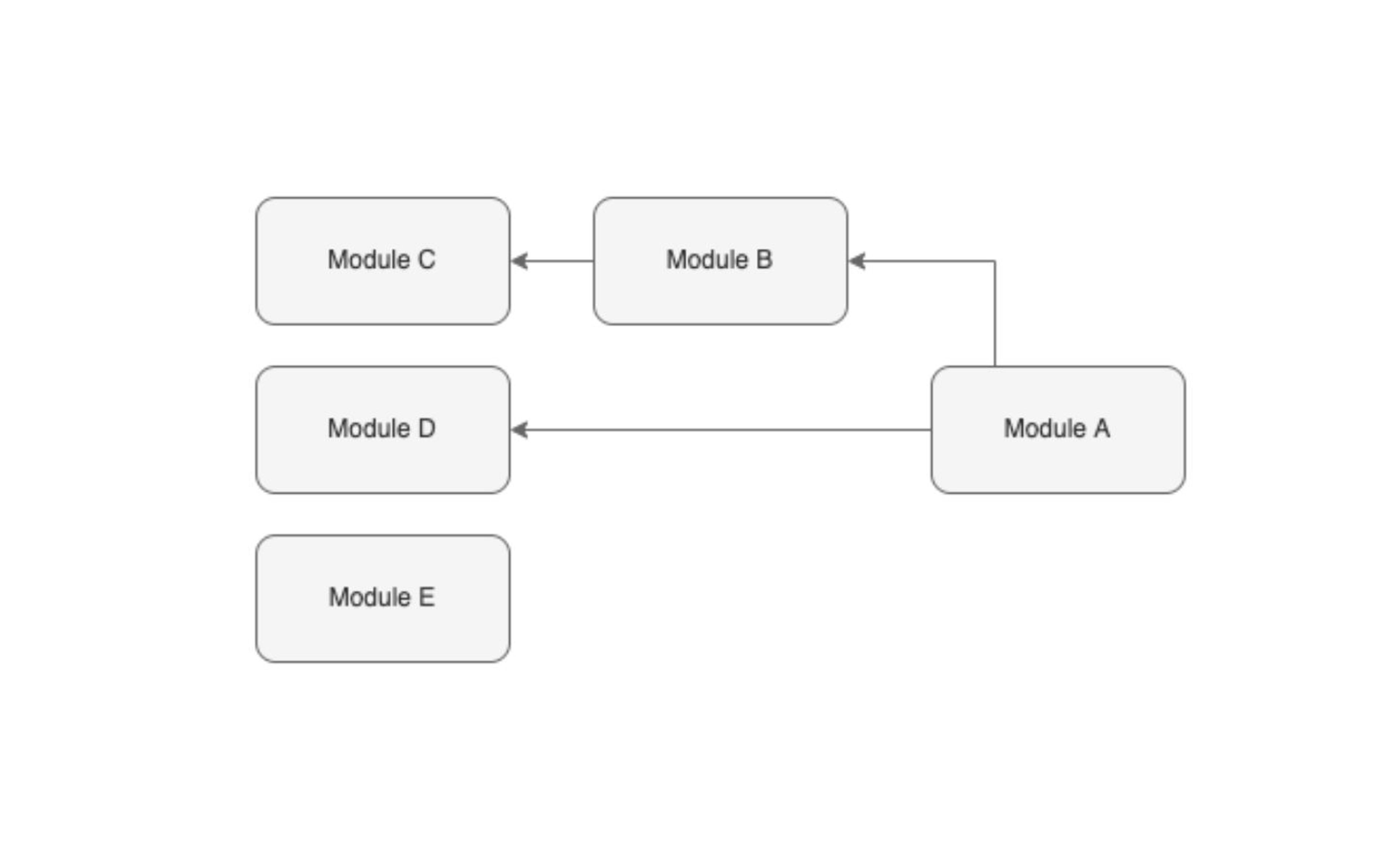
In the following example, we have 5 modules. Module A has two direct dependencies (Module B & Module D), and one indirect dependency (Module C). Module E is totally independent.
We can also interpret it the other way around. Module C has one direct dependent (Module B) and one indirect dependent (Module A). Module D has one direct dependent (Module A). And Module E is totally independent.
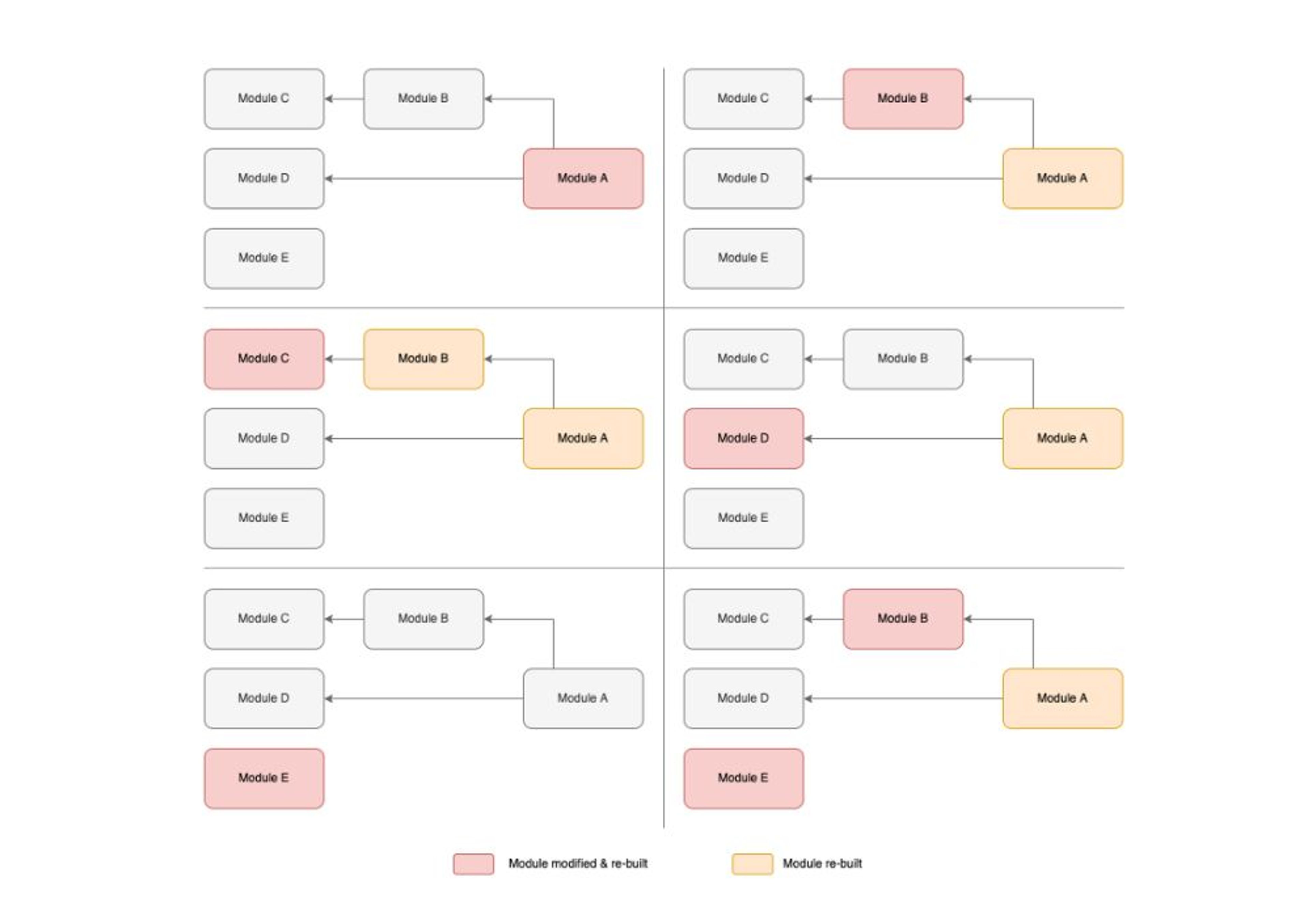
When a module is modified, the objective is to rebuild the module itself, but also all its dependents. In our example, if:
- the Module A is modified, only the Module A is built.
- the Module B is modified, the Module B is built, as well as its direct dependent, the Module A.
- the Module C is modified, the Module C is built, as well as its direct and indirect dependents, the Module B and the Module A.
- the Module D is modified, the Module D is built, as well as its direct dependent, the Module A.
- the Module E is modified, the Module E is built alone since it doesn’t have any dependent.
- both the Module B and the Module E are modified, they are both built, as well as the dependent of the Module B, the Module A.
Now we are able to build only the modules impacted by the modifications. Are we done? Hmm, not really! Currently, the CI is generating results, but our GitHub repository doesn’t really make use of them, it just displays them.
We can probably do better! Let’s configure that!
Use the CI results in our GitHub repository
On GitHub, you have the possibility to protect specific branches of your repository. In our case, we’ve protected our main branch so it’s not possible to push directly on it. The only way to add a commit on main is by using a Pull Request.
Our Pull Requests also need to fulfill some requirements to be merged on main. We want another developer to review and approve the modifications, and we want the CI to confirm that the project can still be built and the tests still pass.
Each time a workflow finishes, either successfully or with failure, CircleCI sends a commit status to GitHub. These statuses appear directly at the bottom of the Pull Request, like in the picture below.
It is also possible to mark a status as Required. In that case, it won’t be possible to merge the Pull Request until we receive a successful status.
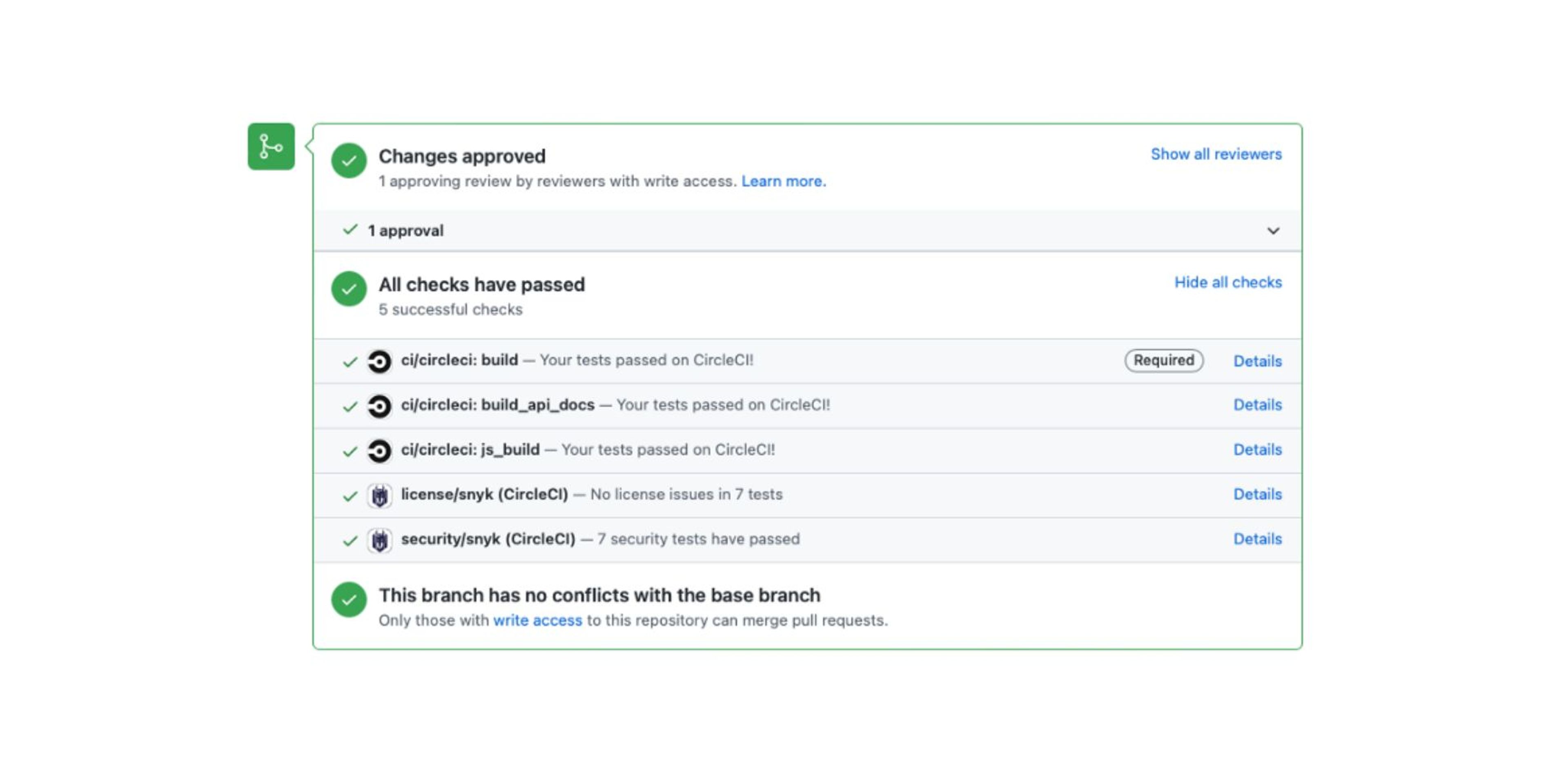
In our configuration, we have set all of our modules’ workflows as Required since we want to be sure that we don’t break something.
Do you see the issue? I hope you do!
Most of the time, we don’t build all the modules! It means that most of the time, CircleCI sends only a part of the commit status expected by GitHub!

Luckily the GitHub API for the commit statuses is public and well-documented. So instead of relying on the default CircleCI statuses, we can use ours!
In setup-workflow, we can manually send successful commit statuses for all the modules that won’t be built. For the modules that are built, we can send a commit status when the workflow ends!
Our CI is now set up and is used by our repository. We are ready to start the adventure!
Our current state
Since the beginning of our project, we have made several modifications to the way the CI works.
One of the first steps was extracting the different scripts provided by circle-advanced-setup-workflow into their own files. It allowed us to review, understand and reformat them. This way, it’s now easier to know exactly what is happening and why! It also means that we have familiarized ourselves with this code and we are able to change it if necessary.
We have also noticed that our config.yml files became long and hard to read. To fix this, we have divided them: each module now has at least one dedicated file for its workflows, one for its jobs, etc... It makes things clearer and easier to maintain!
At some point, our project became so complex that it was too easy to forget to specify an indirect dependent (aka the dependent of a dependent). So we have modified the initial mechanism to not have to!
A graph is now generated from the modules configuration and is used to provide a list of all the modules to build. It also detects potential dependency cycles and generates a visual representation of the relationships between our sub-parts.
circle-advanced-setup-workflow provides a force-all parameter. This is a boolean value that, when set to true, forces the pipeline to build all the modules.
We have renamed it to force and changed its behavior a bit to provide more granularity. Instead of using a boolean value, we are using a string which can be a module, a list of modules, a workflow, or the specific term all.
And finally, we have added a bunch of scripts that modify our configuration files on the fly to do the boring and error-prone work!
One of them adds a final step to every job in order to catch a failure. If this happens, it sends a failure commit status to GitHub, and under certain conditions notifies our engineering channel on Slack.
Another one helps us minimize the size of our configuration files. CircleCI limits the size of the configuration to 3 MB and extracting the multiline scripts automatically is a good way to decrease its size without compromising our development experience!
Conclusion
One year later, we still think that our initial choice for the monorepo architecture was worth it. For sure it made the CI more complex, but the benefit we get from having all of our code in the same place is undeniable.
This is probably not a good fit for every team, especially a small one, since it requires a significant investment in time to set it up correctly, keep it up-to-date, and improve it.
However, if you are in a situation similar to ours, we can only recommend you take the leap! To learn more about how we used Circle CI to make the move to monorepo architecture, read our interview with the Circle CI team.

Notes
- We plan to open-source some of our scripts to facilitate the work of other teams.
- We plan to ask CircleCI if they can integrate some tools natively.
Follow up
We have other topics related to our CI we would like to talk about:
- Our CI configuration in practice.
- Our advanced checkout, or how we check out our code faster and we save time and money!
- Splitting the configuration files to improve the development environment.
- Why we use scripts to alter our CI configuration.
- Fight the 3 MB limit of CircleCI.
- Using GitHub queue (beta) to make your project smoother!
Stay tuned!


